Using Binary trees in Table Database indexes:
If you already know about Databases and Indexes then you probably have heard of binary trees. If not I'll just try to provide a brief idea about indexes and binary trees in this section.
Let's consider our telephone directory. We always look up for the telephone number for some particular name. And how do you do it? Suppose we are searching for the name Mathew Thomas we would first open the directory to some page in the middle. If we see the names starting in 'N' then we know that we have to go back a little. We skip back a few pages and may land on an 'L'. Then we know that we have to go to somewhere in between these two. Our search process continues in this manner. The most important fact is that the telephone directory is sorted on the basis of names. If it weren't so, we wouldn't be able to locate names in the directory. The type of searching we did is similar to a binary search in computer terminology. The requirement for doing a binary search is that the data should be sorted. Binary search is facilitated by storing the data in binary trees.
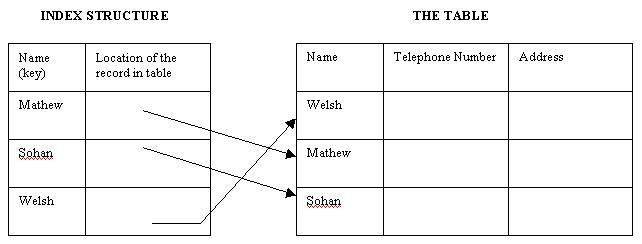
Let us suppose that we have a huge table containing all the records present in the telephone directory (something like an online telephone directory). This table is going to have thousands of rows and maybe 3/4 columns (one for the name, one for the telephone number and maybe 2 for the address fields). We would create an index on one of these columns. An index is created to make it easier for locating records in a table. If we didn't have an index and if we wanted to locate Mathew Thomas in the database, we would have to search through each and every record since Mathew Thomas could be anywhere in the table. This is because when you add rows to a table it could be in any order. I might first enter the name Welsh Smith followed by Mathew Thomas. Thus in the table Welsh Smith would be stored first followed by Mathew Thomas - the data in the table cannot be guaranteed to be ordered. But now if we were to create an index on the name column, our database program will create an index structure. We refer to this as the key (name will be the key in our index structure). The index structure is not part of the actual table. It is like a supplement to the table and it will contain just 2 columns- the key values (in our case this would be the list of names) and a pointer to the actual row in the table. What's the point of storing all the names in an index structure? The names would be stored in an ordered manner (they will be sorted in the index). The following diagram should make things clear:
Each time you add a new record into the table, the index will be reshuffled (to make it ordered) but the table will remain the same (the reason for this is that our table could have many columns. In that case it would become a huge burden on the system to try and reshuffle the rows of the table. Instead shuffling around the index structure is relatively easier since there are only two columns). Now where does a binary tree come in? You must have guessed by now. We could store all the name in a node (with the name that appears somewhere in the middle as the root). Put the rest of the names in the respective places depending on whether they are greater than the root value or not. And then it is easy to implement our binary search algorithm once we have the binary tree in place.
I don't want to get into too much of details about indexes and databases over here in C++. If you want to know more on Indexes you could check out some tutorials that I've written in the following link:
www.techneurons.com/Career/techtutor.asp
Go back to the Contents Page 2
Copyright © 2004 Sethu Subramanian All rights reserved.